DeepSeek-R1-0528 release
The updated version R1-0528 performs better than the first version R1 in all areas. The model has not changed architecturally, only the training itself has been improved.
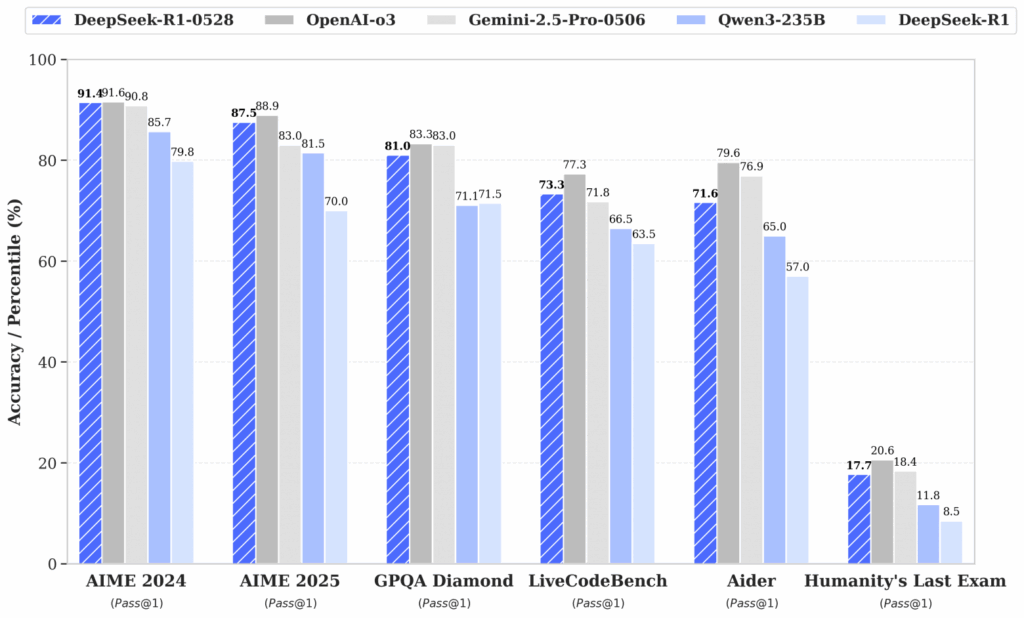
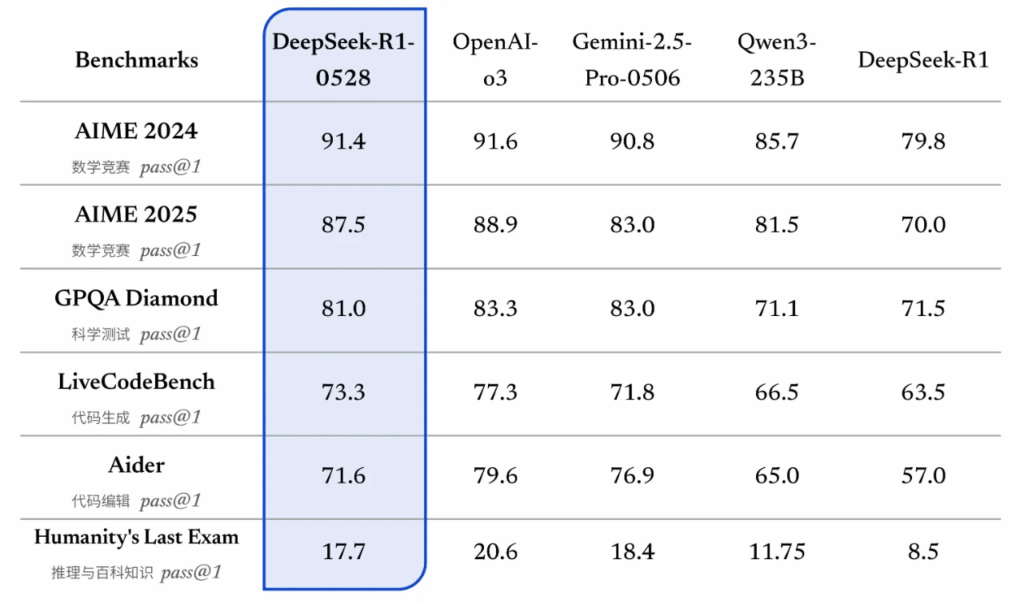
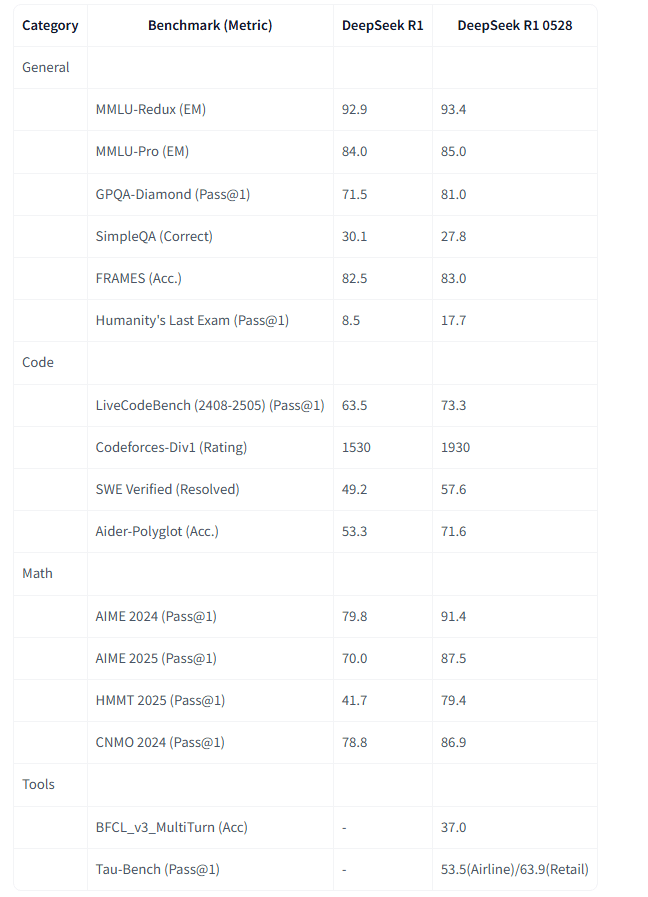
In LiveBench the model shows not bad results.
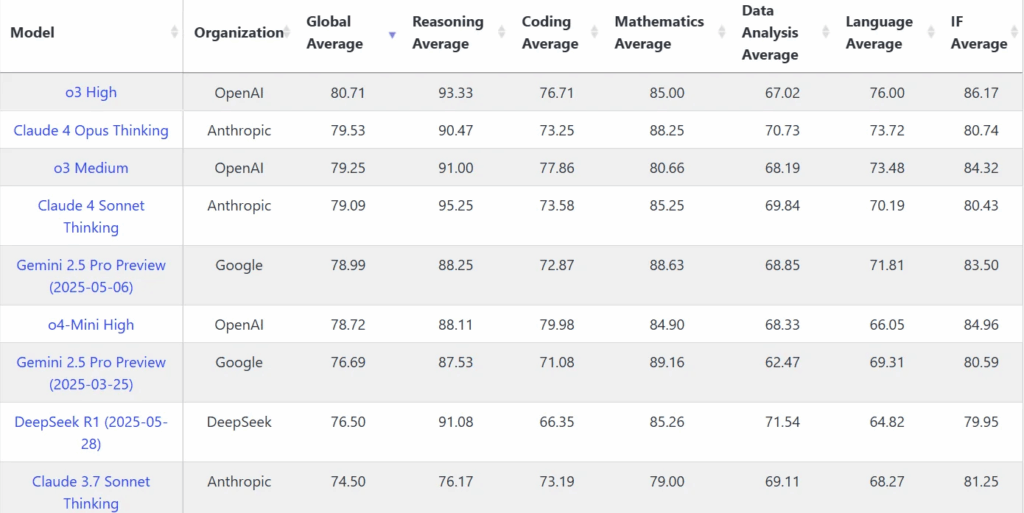
In addition to the updated R1, the DeepSeek-R1-0528-Qwen3-8B version has been introduced. This distillate R1-0528 is made on the Qwen3-8B model.
How to run DeepSeek-R1-0528
GGUF to run locally: https://huggingface.co/unsloth/DeepSeek-R1-0528-GGUF
The 1.78-bit version requires 185gb + context size. In the new llama.cpp and ik_llama version, override tensor -ot or –override-tensor is available. It uses regexp to control which tensors will be directed where. For example, the command:
-ot ".ffn_.*_exps.=CPU" -ngl 99
In this case, MoE weights, that is, the weights of individual experts are sent to the CPU and the total weights go to the GPU. In this way, a single GPU will give a good speedup.
Before, only whole layers, i.e., individual specific experts, were sent to the GPU, since DeepSeek is a MoE model with only 37B weights active at each step of computing the next token. Because of this distribution, those layers that hit the GPU will not be executed every step, but if you load the general tensors that are needed at each step onto the GPU, it will give a speedup.
If there is not enough memory to run with ssd, you can try adding the
--ubatch-size 1
– command, this will allow pp to be calculated in batches of 1 instead of 512 if the ssd is not performant enough.
Try Online
Free api and chat on openrouter:
- https://openrouter.ai/deepseek/deepseek-r1-0528:free
- https://openrouter.ai/deepseek/deepseek-r1-0528-qwen3-8b:free
The new version is already up and running at https://chat.deepseek.com/